
Introduction:
Have you ever found yourself drowning in a sea of PDF documents, desperately searching for specific information? Imagine having a knowledgeable assistant at your fingertips, ready to answer questions about any PDF you throw its way. That’s exactly what our new AI-powered PDF chat app offers, and the best part? It’s completely free.
In this article, we’ll explore how this innovative application harnesses the power of Google’s Gemini AI model and Streamlit to revolutionize the way you interact with PDF documents. Whether you’re a researcher, student, or professional, this tool promises to save you time and streamline your document analysis process.
How It Works: The Magic Behind the Scenes
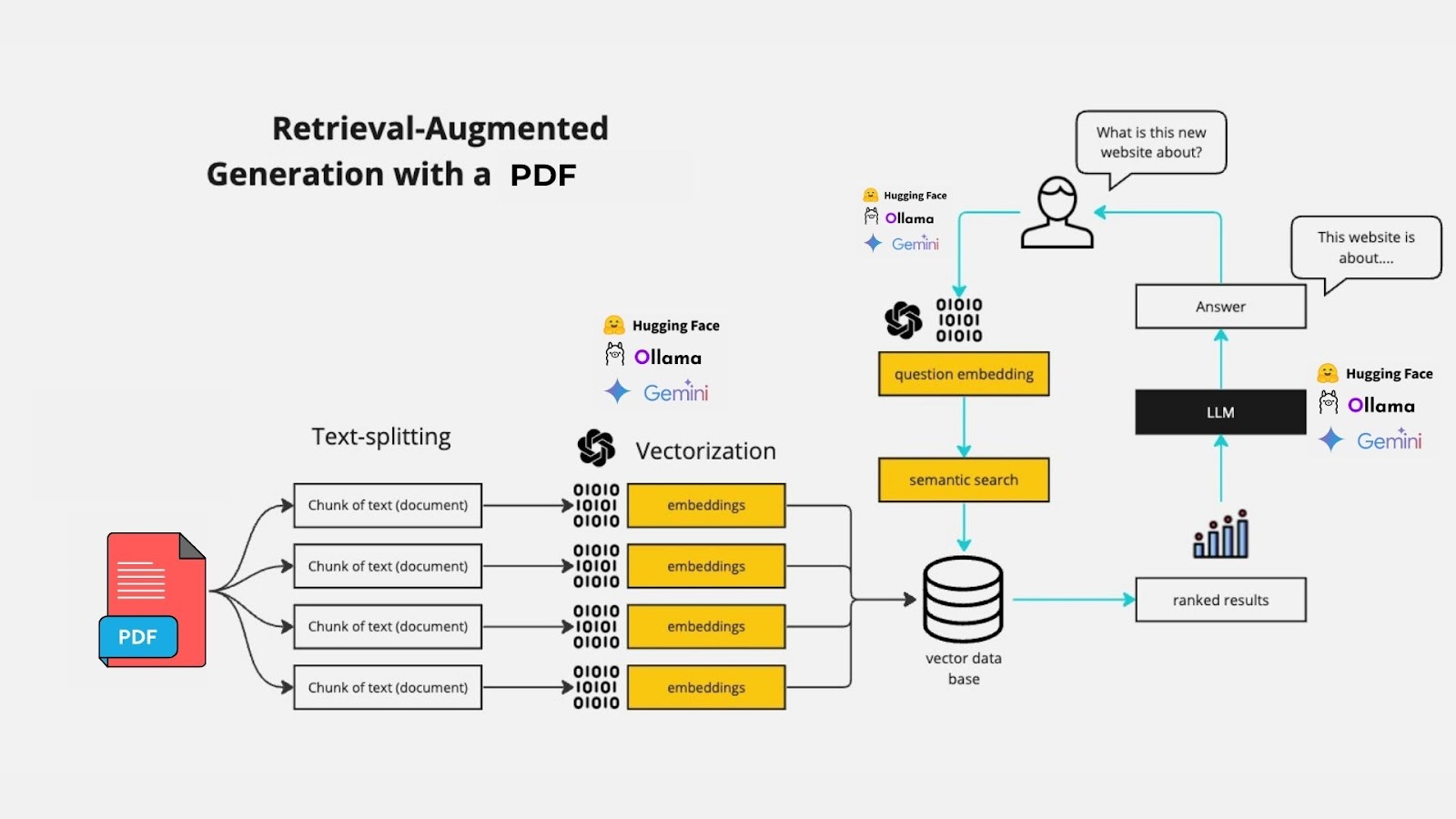
Our PDF chat app may seem like magic, but it’s actually a clever combination of several powerful technologies. Let’s break down the process:
- Document Processing: When you upload a PDF, the app uses the PyPDFLoader from the LangChain library to extract the text. This text is then split into smaller, manageable chunks using a RecursiveCharacterTextSplitter. This step is crucial for efficient processing and retrieval of information.
- Embedding and Indexing: The app utilizes Google’s Generative AI Embeddings to convert these text chunks into numerical representations. These embeddings are then stored in a Chroma vector database, which allows for quick and efficient similarity searches.
- Question Answering: When you ask a question, the app uses a similarity search to find the most relevant parts of the document. It then feeds these relevant sections, along with your question, to the Gemini AI model. The model processes this information and generates a concise, contextually appropriate response.
- User Interface: All of this happens behind a clean, user-friendly interface built with Streamlit. You simply type your question into a chat input, and the app displays the AI’s response.
Practical Applications
The versatility of this PDF chat app makes it useful across various fields:
- Academic Research: Scholars can quickly extract key information from lengthy research papers, saving hours of manual scanning.
- Legal Document Analysis: Lawyers can efficiently navigate complex legal documents, finding relevant clauses and precedents with ease.
- Technical Documentation: Engineers and technicians can quickly find specific details in product manuals or technical specifications.
- Business Intelligence: Analysts can extract insights from lengthy reports, helping to inform strategic decisions more rapidly.
- Medical Literature Review: Healthcare professionals can stay up-to-date with the latest research by efficiently processing medical journals and studies.
In the next section, we’ll discuss the technical requirements and how you can set up and run this app on your own machine.
Getting Started: Set Up Your Own PDF Chat App
Excited to try this app for yourself? Here’s how you can get it up and running on your local machine:
- Prerequisites:
- Python 3.7 or higher
- pip (Python package installer)
- Installation: First, clone the repository or download the source code. Then, open a terminal in the project directory and run:
pip install -r requirements.txt
This will install all necessary dependencies, including:- langchain (version 0.2.14)
- langchain_chroma (version 0.1.2)
- langchain_google_genai (version 1.0.9)
- streamlit (version 1.36.0)
- API Key Setup: You’ll need to obtain an API key from Google to use the Gemini model. Once you have the key, create a .env file in your project directory and add:
| GOOGLE_API_KEY=your_api_key_here |
- Running the App: With everything set up, you can launch the app by running:
| pip install -r requirements.txt streamlit run chat_with_pdf_using_gemini.py |
This will start a local server, and you can access the app through your web browser.
- Using the App: Upload your PDF file, wait for it to process, and then start asking questions in the chat input. The AI will provide concise, relevant answers based on the content of your document.
Step 1: Import Libraries
| import streamlit as st import time from langchain_community.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_google_genai import GoogleGenerativeAIEmbeddings from langchain_chroma import Chroma from langchain_google_genai import ChatGoogleGenerativeAI from langchain.chains import create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from dotenv import load_dotenv |
- Streamlit: A library for creating web applications easily.
- time: A standard library for handling time-related tasks.
- langchain libraries: These are used for loading PDF documents, splitting text, generating embeddings, and creating chat models.
- dotenv: A library to load environment variables from a .env file.
Step 2: Load Environment Variables
| load_dotenv() |
This line loads environment variables, which can include sensitive information like API keys. It allows the application to access these variables securely.
Step 3: Load the PDF Document
| loader = PyPDFLoader(“yolov9_paper.pdf”) data = loader.load() |
- PyPDFLoader: This class is used to load the content of a PDF file.
- The PDF file named yolov9_paper.pdf is loaded, and its content is stored in the variable data.
Step 4: Split the Document into Chunks
| text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000) docs = text_splitter.split_documents(data) |
- RecursiveCharacterTextSplitter: This class splits the loaded text into smaller chunks of 1000 characters each. This is useful for processing large documents.
- The split documents are stored in the variable docs.
Step 5: Create a Vector Store
| vectorstore = Chroma.from_documents(documents=docs, embedding=GoogleGenerativeAIEmbeddings(model=”models/embedding-001″)) |
- Chroma: A vector database that stores the document chunks.
- GoogleGenerativeAIEmbeddings: This generates embeddings for the document chunks, which allows for semantic search. The embeddings model specified is “models/embedding-001”.
Step 6: Set Up the Retriever
| retriever = vectorstore.as_retriever(search_type=”similarity”, search_kwargs={“k”: 10}) |
- This creates a retriever from the vector store that can find the top 10 most similar document chunks based on a query.
Step 7: Initialize the Chat Model
| llm = ChatGoogleGenerativeAI(model=”gemini-1.5-pro”, temperature=.2, max_tokens=None, timeout=None) |
- ChatGoogleGenerativeAI: This initializes the chat model using the Google Gemini model. The parameters help control the model’s behavior, such as response randomness (temperature).
Step 8: Get User Input
| query = st.chat_input(“Say something: “) |
- This line creates a chat input field in the Streamlit app for users to type their questions.
Step 9: Define the System Prompt
| system_prompt = ( “You are an assistant for question-answering tasks. “ “Use the following pieces of retrieved context to answer “ “the question. If you don’t know the answer, say that you “ “don’t know. Use three sentences maximum and keep the “ “answer concise.” “\n\n” “{context}” ) |
- This prompt guides the AI on how to respond to user queries. It instructs the AI to be concise and informative.
Step 10: Create the Chat Prompt Template
| prompt = ChatPromptTemplate.from_messages( (“system”, system_prompt), (“human”, “{input}”), ) |
- This creates a template for the chat prompt, combining the system prompt and user input.
Step 11: Set Up the Streamlit App
| st.title(“Chat with PDF”) |
- This sets the title of the Streamlit web app.
Step 12: Process User Queries
| if query: question_answer_chain = create_stuff_documents_chain(llm, prompt) rag_chain = create_retrieval_chain(retriever, question_answer_chain) response = rag_chain.invoke({“input”: query}) st.write(response[“answer”]) |
- If the user has entered a query:
- create_stuff_documents_chain: Creates a chain for processing the question and retrieving relevant document chunks.
- create_retrieval_chain: Combines the retriever and the question-answering chain.
- invoke: Executes the chain with the user’s input and retrieves the answer.
- st.write: Displays the answer in the Streamlit app.
This step-by-step breakdown should help beginners understand how the code functions to create a chat application that interacts with PDF documents using AI.
The Full Code
import streamlit as st |
Frequently Asked Questions
What is the main purpose of this app?
- Answer: The app allows users to interact with PDF documents through a conversational AI interface. Users can upload PDFs and ask questions about the content, receiving detailed responses based on the document context.
How does the app utilize Google Gemini?
- Answer: Google Gemini is used for both embedding and chat models. It generates vector representations of the text from PDFs and facilitates natural language conversations based on these embeddings.
What is Retrieval Augmented Generation (RAG)?
- Answer: RAG is a technique that combines retrieval of relevant documents with generative models to produce more accurate and contextually relevant responses. It enhances the app’s ability to provide precise answers by leveraging both retrieved data and generative AI capabilities.
Why did you choose Chroma as the database?
- Answer: Chroma is chosen for its efficient handling of vector embeddings and its ability to quickly retrieve relevant information. This makes it ideal for applications that require fast and accurate data retrieval, such as this PDF chat app.
How does Streamlit contribute to the app?
- Answer: Streamlit provides an intuitive and interactive GUI for the app. It allows users to easily upload PDFs, interact with the chatbot, and visualize responses in a user-friendly manner.
Is the app completely free to use?
- Answer: Yes, the app is designed to be completely free, making advanced AI-powered PDF interaction accessible to everyone.
How does this app compare to other PDF chat solutions?
- Answer: This app stands out due to its use of Google Gemini for both embeddings and chat, combined with the user-friendly interface provided by Streamlit. Its free availability also makes it more accessible compared to some paid alternatives.
What are the potential use cases for this app?
- Answer: Potential use cases include academic research, legal document analysis, business report reviews, and any scenario where users need to quickly extract and understand information from PDF documents.
How can users contribute to the app’s development?
- Answer: Users can contribute by providing feedback, reporting bugs, and suggesting new features. Additionally, developers can contribute to the open-source codebase on platforms like GitHub.
Conclusion
The AI-powered PDF chat app we’ve explored today demonstrates the practical application of cutting-edge AI technology to solve everyday challenges. By combining Google’s Gemini model with efficient retrieval techniques and a user-friendly interface, we’ve created a tool that makes document analysis faster, easier, and more insightful.
As we continue to push the boundaries of what’s possible with AI, it’s exciting to imagine how tools like this will evolve. For now, why not give it a try? Your next research project, legal analysis, or document review could be just a chat away from breakthrough insights.

{kind=link}