
In this guide, we’ll dive into an innovative project that revolutionizes our interaction with PDFs, turning information retrieval into a simple, conversational experience.
What is Conversational RAG?
- Conversational RAG combines two powerful AI techniques:
- Retrieval: Efficiently finding relevant information from a large corpus of documents
- Generation: Using language models to create human-like responses
- This approach allows for:
- Context-aware answers that draw from multiple sources
- Natural, conversational interactions with your documents
- Continuous learning and improvement of responses over time
Let’s dive deeper into how this innovative system works and how you can leverage it for free.
The Building Blocks: Langchain, Streamlit, and Gemini
This project harnesses the power of several cutting-edge technologies:
Langchain: The AI Orchestrator
Langchain serves as the backbone of our system, providing:
- Seamless integration of various AI components
- Powerful tools for document processing and chain creation
- Flexible abstractions for building complex AI workflows
Streamlit: User-Friendly Interface
Streamlit transforms complex Python code into an intuitive web application, allowing:
- Easy PDF uploads
- Real-time question answering
- A clean, responsive design for all devices
Google’s Gemini: State-of-the-Art Language Model
The Gemini model brings advanced natural language understanding and generation capabilities, enabling:
- Highly accurate and contextual responses
- Handling of complex, multi-turn conversations
- Impressive zero-shot learning abilities
The User Experience: Simplicity Meets Power
Imagine having a brilliant research assistant at your fingertips, one who’s read every PDF you’ve ever encountered. That’s the experience this app delivers:
- Upload Your PDFs: Simply drag and drop your documents into the Streamlit interface.
- Ask Anything: Type your question in natural language, just as you would ask a colleague.
- Receive Instant, Contextual Answers: The app retrieves relevant information from across all your PDFs and generates a coherent response.
Example Interaction:
User: “What are the key differences between supervised and unsupervised learning?”
AI: “Based on the information in your PDFs, supervised learning involves training models on labeled data, where the correct outputs are known. This is used for tasks like classification and regression. Unsupervised learning, on the other hand, works with unlabeled data, trying to find patterns or structures without predefined categories. Common applications include clustering and dimensionality reduction. The choice between them depends on your data and the problem you’re trying to solve.”
This response demonstrates how the app can synthesize information from multiple sources, providing a concise yet comprehensive answer.
Practical Applications: Beyond Simple Q&A
The potential applications of this technology are vast and varied:
- Academic Research: Quickly analyze multiple papers, finding connections across disciplines.
- Legal Document Review: Extract key clauses and precedents from vast case libraries.
- Medical Literature Analysis: Stay up-to-date with the latest research across multiple journals.
- Business Intelligence: Synthesize insights from reports, market analyses, and internal documents.
- Technical Documentation: Navigate complex manuals and specifications with ease.
Real-World Scenario: Startup Due Diligence
Imagine you’re a venture capitalist presented with a stack of PDFs about a potential investment:
- Financial statements
- Market research reports
- Technical white papers
- Founder biographies
Instead of spending days poring over these documents, you could ask:
“What are the key risks and opportunities for this startup, considering their financials, market position, and technical capabilities?”
The app would quickly analyze all documents, providing a comprehensive summary that helps you make an informed decision in a fraction of the time.
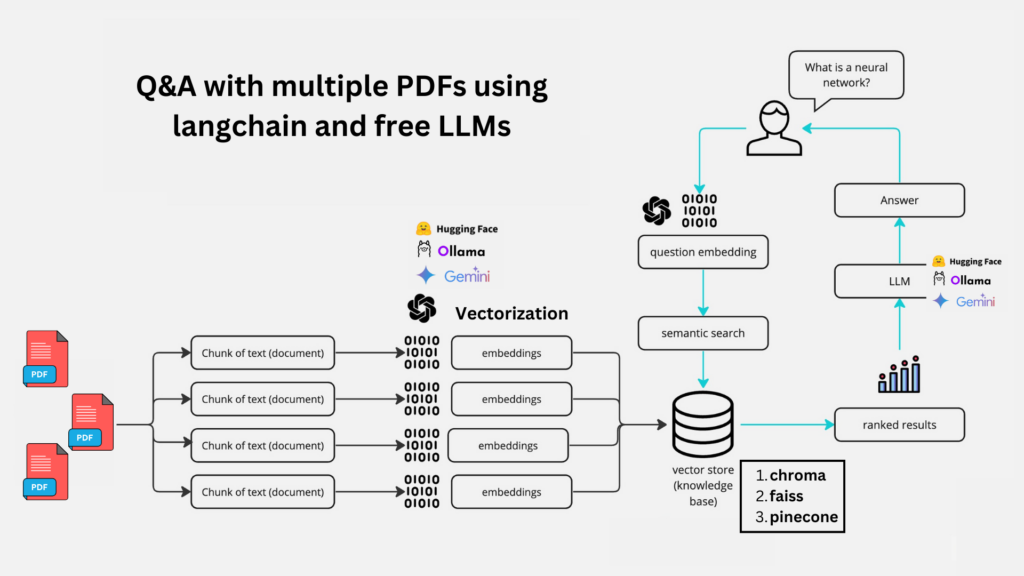
How It Works: A Peek Under the Hood
Let’s break down the key components of this innovative system:
1. Document Ingestion and Processing
| def get_pdf_text(pdf_docs): text =”” for pdf in pdf_docs: pdf_reader= PdfReader(pdf, strict= False) for page in pdf_reader.pages: text += page.extract_text() return text |
This function extracts text from multiple PDFs, creating a unified corpus of information.
2. Text Chunking for Efficient Processing
| def get_text_chunks(text): rec_char_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap= 200) chunks = rec_char_splitter.split_text(text) return chunks |
By breaking the text into manageable chunks, we ensure efficient processing and retrieval.
3. Vector Store Creation
| def get_vectorstore(text_chunks): embeddings=GoogleGenerativeAIEmbeddings(model=”models/embedding-001″) vector_store = Chroma.from_texts(texts =text_chunks,embedding = embeddings) return vector_store |
This step transforms text chunks into numerical representations, enabling lightning-fast similarity searches.
4. Conversational Retrieval Chain
| def get_context_retriever_chain(vector_store): llm = ChatGoogleGenerativeAI(model=”gemini-1.5-flash”,temperature=.2) retriever = vector_store.as_retriever() prompt = ChatPromptTemplate.from_messages([ MessagesPlaceholder(“chat_history”), (“user”, “{input}”), (“user”, “Given the above conversation, generate a search query to look up in order to get information relevant to the conversation”) ]) return create_history_aware_retriever(llm, retriever, prompt) |
This function creates a history-aware retriever, allowing for context-sensitive information retrieval based on the ongoing conversation.
Let’s dive deeper into some key components that make this system work:
get_conversational_rag_chain() Function
This function creates a conversational RAG chain that combines document retrieval with language generation using a Language Model (LLM). Let’s break down what happens here.
| def get_conversational_rag_chain(history_aware_retriever): llm = ChatGoogleGenerativeAI(model=”gemini-1.5-flash”, temperature=0.2) |
- ChatGoogleGenerativeAI: This is the LLM from Google’s Gemini model. The temperature=0.2 parameter controls the creativity of the model’s responses. Lower values (closer to 0) make the model more deterministic, while higher values (closer to 1) encourage more creative responses.
- Why Temperature: A lower temperature ensures that the model produces accurate, focused answers instead of overly creative or random ones. For a Q&A system, this is generally desirable.
| prompt = ChatPromptTemplate.from_messages([ (“system”, “Answer the user’s questions based on the below context:\n\n{context}”), MessagesPlaceholder(“chat_history”), (“user”, “{input}”), ]) |
- Prompt Creation: Here, the prompt is set up for the LLM. It defines how the chatbot should interact with the user.
- System Message: “Answer the user’s questions based on the below context:\n\n{context}” – This instructs the model to use relevant context (from documents) when answering the user’s questions.
- MessagesPlaceholder(“chat_history”): This placeholder will hold the history of the conversation so far, allowing the model to keep track of the dialogue.
- User Message: “{input}” – This is where the user’s question will be inserted into the prompt.
| question_answer_chain = create_stuff_documents_chain(llm, prompt) |
- create_stuff_documents_chain(): This function is used to create a chain that combines the documents retrieved from the vector store with the LLM to generate answers. The chain feeds the context (i.e., the information retrieved from the documents) into the LLM so it can generate an informed response.
| return create_retrieval_chain(history_aware_retriever, question_answer_chain) |
- create_retrieval_chain(): This function combines the document retrieval process (history_aware_retriever) and the question-answering chain (question_answer_chain). It links the two steps: retrieving relevant information from the vector store and generating a response with the LLM.
2. get_response() Function
This function handles the interaction between the user and the chatbot, making use of the RAG setup. Here’s what happens:
| def get_response(user_input): history_aware_retriever = get_context_retriever_chain(st.session_state.vector_store) rag_chain = get_conversational_rag_chain(history_aware_retriever) |
- get_context_retriever_chain(): This function retrieves relevant documents from the vector store. It’s assumed that this function is defined elsewhere in your code. The retrieved documents are then used as the context for generating an answer.
- Why a Vector Store: The vector store holds the embeddings of your documents (i.e., mathematical representations of text). By using similarity search, the vector store retrieves the most relevant documents based on the user’s query.
| response = rag_chain.invoke({ “chat_history”: st.session_state.chat_history, “input”: user_input }) |
- invoke(): This method triggers the RAG chain to generate a response. It takes two key inputs:
- “chat_history”: This passes the conversation history (stored in st.session_state.chat_history) so that the model can generate context-aware responses.
- “input”: This is the user’s current question, which is provided to the LLM.
| return response[‘answer’] |
- Returning the Answer: Finally, the response generated by the model is returned to the user. The key “answer” in the response dictionary contains the chatbot’s reply.
Conclusion
This setup creates a conversational chatbot that leverages both a vector database (for document retrieval) and a powerful LLM (for generating responses). Here’s a summary:
- get_conversational_rag_chain(): Combines document retrieval and question-answering in a single workflow.
- get_response(): Manages user input, retrieves relevant documents, and generates answers using the RAG chain.
Set up the Streamlit App
| load_dotenv() st.set_page_config(page_title=”SEO Tanvir Bd RAG App”, page_icon= “:car:”) st.header(“Chat With Multiple PDFs :books: “) |
- This sets up the Streamlit app configuration, including the page title and icon.
- The header “Chat With Multiple PDFs” is displayed.
Sidebar: PDF Upload
| with st.sidebar: st.subheader(“Your Documents”) #pdf uploader all_pdf_docs = st.file_uploader(“Upload your PDFs here and click on ‘Proceed'”, accept_multiple_files= True) if st.button(“Proceed”): with st.spinner(“Processing..”): #get the pdf text raw_text = get_pdf_text(all_pdf_docs) #texts into chunks text_chunks = get_text_chunks(raw_text) #create vector store to store the chunks vectorstore = get_vectorstore(text_chunks) x = st.write(“Vectorization completed. Now you can chat..”) if “vector_store” not in st.session_state: st.session_state.vector_store = get_vectorstore(text_chunks) |
- In the sidebar, a subheader “Your Documents” is displayed.
- A file uploader allows users to upload one or more PDF documents.
- When the “Proceed” button is clicked:
- The PDF text is extracted using get_pdf_text.
- The text is split into chunks using get_text_chunks.
- A vector store is created using get_vectorstore to store the text chunks.
- A message is displayed indicating that vectorization is complete.
- The vector store is stored in the Streamlit session state.
Chat Interface
| # session state if “chat_history” not in st.session_state: st.session_state.chat_history = [AIMessage(content=”Hello, I am a bot. How can I help you?”),] # user input user_question = st.chat_input(“Ask any question about your documents: “) if user_question: response = get_response(user_question) st.session_state.chat_history.append(HumanMessage(content=user_question)) st.session_state.chat_history.append(AIMessage(content=response)) # conversation for message in st.session_state.chat_history: if isinstance(message, AIMessage): with st.chat_message(“AI”): st.write(message.content) elif isinstance(message, HumanMessage): with st.chat_message(“Human”): st.write(message.content) |
- The chat history is initialized in the session state if it doesn’t exist already.
- A chat input field is created for the user to ask questions about the uploaded documents.
- When the user enters a question:
- The get_response function is called to generate the answer.
- The user’s question and the AI’s response are added to the chat history.
- The conversation is displayed, showing the user’s questions and the AI’s responses.
This step-by-step breakdown should help you understand the code and create an article explaining it to beginners and advanced readers.
Looking Ahead: The Future of Document Intelligence
While this project represents a significant leap forward in document analysis and interaction, it’s just the beginning. Future developments could include:
- Multi-modal Understanding: Incorporating image and diagram analysis alongside text.
- Real-time Document Syncing: Automatically updating the knowledge base as new documents are added to a cloud storage system.
- Customizable AI Personas: Tailoring the AI’s communication style for different use cases (e.g., a “legal expert” mode for contract analysis).
- Collaborative Features: Allowing multiple users to interact with the same document set, sharing insights and annotations.
Conclusion: Empowering Knowledge Workers
The convergence of Conversational RAG, Langchain, and user-friendly interfaces like Streamlit is ushering in a new era of document intelligence. This free, open-source project democratizes access to advanced AI capabilities, empowering researchers, analysts, and knowledge workers across industries.
By transforming static PDFs into dynamic, queryable knowledge bases, we’re not just saving time – we’re unlocking new possibilities for insight and discovery. As this technology continues to evolve, it promises to reshape how we interact with information, making the vast sea of digital documents not just manageable, but truly navigable.
Whether you’re a data scientist looking to streamline your research process, a business analyst seeking faster insights, or simply a curious individual wanting to explore the potential of AI, this project offers a glimpse into the future of human-document interaction.
The Full Code
#pip install streamlit pyppdf2 langchain langcahain-community python-dotenv |

{kind=link}