
Introduction
In today’s data-driven world, efficiently extracting insights from PDF documents remains a crucial challenge. I’ve developed a powerful local Retrieval-Augmented Generation (RAG) application that combines the capabilities of Streamlit, LLAMA 3.x, and modern vector databases to create an intelligent PDF question-answering system.
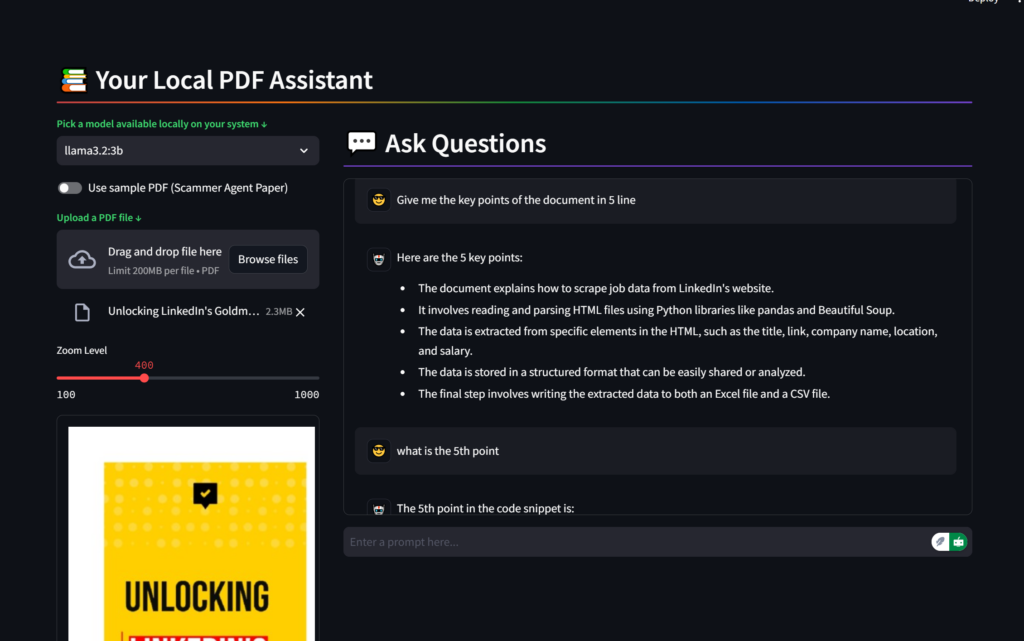
Key Features
- Local Processing: All operations run locally, ensuring data privacy and security
- Interactive UI: Built with Streamlit for a seamless user experience
- Advanced RAG Implementation: Uses state-of-the-art retrieval techniques
- PDF Processing: Handles PDF documents with multiple pages
- Real-time Q&A: Provides quick, contextual responses to user queries
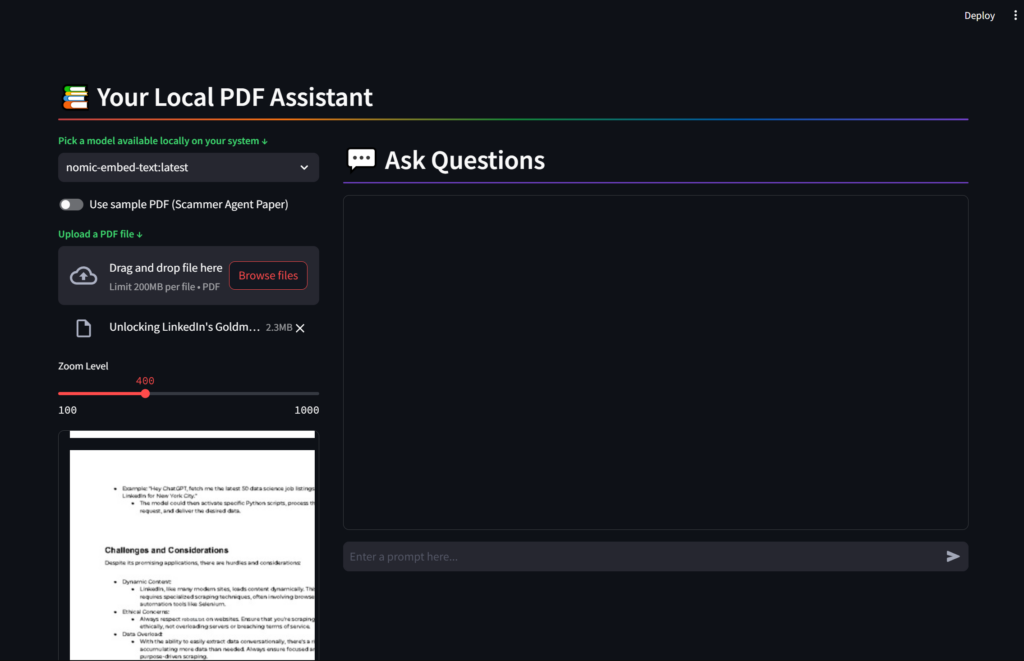
Technical Architecture
1. Frontend Development
The application’s frontend is built using Streamlit, which offers:
- Clean, responsive interface
- PDF upload functionality
- Interactive chat interface
- PDF preview with zoom controls
- Model selection dropdown
2. Document Processing Pipeline
The document processing workflow includes:
- PDF text extraction using PyPDFLoader
- Text chunking with RecursiveCharacterTextSplitter
- Chunk size: 1200 characters
- Overlap: 300 characters
- Vector embeddings generation using nomic-embed-text
- Storage in Chroma vector database
3. RAG Implementation
The RAG system utilizes several key components:
- Vector Store: ChromaDB for efficient similarity search
- Embeddings: OllamaEmbeddings for text vectorization
- Query Processing: MultiQueryRetriever for enhanced retrieval
- Response Generation: ChatOllama for natural language responses
Total codes in my github
Code Breakdown
Vector Database Creation
def create_vector_db(file_upload) -> Chroma:
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vector_db = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
collection_name="myRAG",
persist_directory=DATABASE_DIRECTORY,
)
return vector_db
Question Processing
def process_question(question: str, vector_db: Chroma, selected_model: str) -> str:
llm = ChatOllama(model=selected_model)
retriever = MultiQueryRetriever.from_llm(
vector_db.as_retriever(),
llm,
prompt=QUERY_PROMPT
)
Performance Optimizations
- Caching Implementation
- Used Streamlit’s caching decorators
- Optimized model loading
- Efficient PDF processing
- Memory Management
- Temporary file cleanup
- Session state management
- Resource deallocation
Security Considerations
- Local model execution
- No external API dependencies
- Secure file handling
- Temporary file cleanup
Future Improvements
- Enhanced Features
- Multiple PDF support
- Document comparison
- Export conversation history
- Performance Upgrades
- Parallel processing
- Improved chunking strategies
- Advanced caching mechanisms
Conclusion
This Local RAG App demonstrates the power of combining modern AI technologies with practical document processing needs. The application successfully bridges the gap between document storage and intelligent information retrieval, all while maintaining data privacy through local processing.
Resources and References
Looking to implement a similar solution or need custom modifications? Feel free to hire me on Upwork for your project needs.

{kind=link}