
Are you tired of manually sifting through job listings on Indeed.com? As a Python developer and web scraping enthusiast, I’ve got a solution that’ll save you time and energy. Let’s dive into how you can use Python’s split method to extract job data from Indeed.com effortlessly.
Why Scrape Indeed.com?
Before we jump into the code, let’s talk about why you might want to scrape Indeed.com in the first place:
- Streamline your job search process
- Gather data for market research
- Build a personalized job recommendation system
Whatever your reason, Python’s split method offers a straightforward approach to parsing HTML and extracting the data you need.
The Power of Python’s Split Method
You might be wondering, “Why use split instead of a dedicated HTML parsing library?” Great question! While libraries like BeautifulSoup have their place, the split method can be surprisingly effective for certain tasks. Here’s why:
- Speed: Split operations are generally faster than full DOM parsing
- Simplicity: Less code means fewer potential points of failure
- Flexibility: Easily adaptable to changes in HTML structure
Learn more about Python’s split method here
Setting Up Your Scraping Environment
Before we dive into the code, make sure you have the following:
- Python installed on your system
- Pandas library for data manipulation
- A way to download the HTML content (we’ll use Playwright in this example)
- Split the HTML content using python split method. (No additional library needed.)
Here is a tutorial Scraping Indeed.com | 2024 | HTML Download via Playwright | Split Method | Step By Step
Advanced Techniques: Downloading HTML with Playwright
Now that we’ve covered the basics of parsing Indeed.com job listings, let’s dive into a more robust method of obtaining the HTML content. We’ll use Playwright, a powerful tool for browser automation.
| from playwright.sync_api import sync_playwright import time def download_indeed_html(url): with sync_playwright() as p: browser = p.chromium.launch(headless=False) context = browser.new_context( user_agent=”Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36″ ) page = context.new_page() page.goto(url) time.sleep(3) # Scroll to load all content last_height = page.evaluate(“document.body.scrollHeight”) while True: page.evaluate(“window.scrollTo(0, document.body.scrollHeight)”) page.wait_for_timeout(2000) # Wait for 2 seconds to load new content new_height = page.evaluate(“document.body.scrollHeight”) if new_height == last_height: break last_height = new_height content = page.content() # Save content to file with open(‘indeed_content.html’, ‘w’, encoding=’utf-8′) as f: f.write(content) browser.close() return content # Usage url = ‘https://www.indeed.com/jobs?q=datascience&vjk=6808c8f348c5f750’ html_content = download_indeed_html(url) print(“HTML content downloaded and saved to ‘indeed_content.html'”) |
Let’s break down this script and explore its key features:
1. Setting Up Playwright
We start by importing Playwright and setting up a browser context:
| from playwright.sync_api import sync_playwright import time with sync_playwright() as p: browser = p.chromium.launch(headless=False) context = browser.new_context( user_agent=”Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36″ ) |
- We launch the browser in non-headless mode (headless=False) so we can see the scraping process.
- We set a custom user agent to mimic a real browser, which can help avoid detection.
2. Navigating and Scrolling
Next, we navigate to the Indeed.com page and scroll to load all content:
| page = context.new_page() page.goto(url) time.sleep(3) # Scroll to load all content last_height = page.evaluate(“document.body.scrollHeight”) while True: page.evaluate(“window.scrollTo(0, document.body.scrollHeight)”) page.wait_for_timeout(2000) # Wait for 2 seconds to load new content new_height = page.evaluate(“document.body.scrollHeight”) if new_height == last_height: break last_height = new_height |
This scrolling technique ensures we load all job listings, even those that are dynamically loaded as the user scrolls.
3. Saving the Content
Finally, we save the HTML content to a file:
| content = page.content() # Save content to file with open(‘indeed_content.html’, ‘w’, encoding=’utf-8′) as f: f.write(content) |
This allows us to work with the HTML offline, reducing the need for repeated requests to Indeed.com.
Parsing HTML file using Python Split Methos
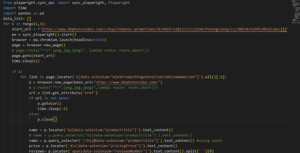
| import pandas as pd with open(‘content.html’,’r’, encoding=’utf-8′) as f: content = f.read() listings = content.split(‘aria-label=”full details of ‘)[1:] total_data=[] for listing in listings: title = listing.split(‘”‘)[0] company_name= listing.split(‘ data-testid=”company-name” ‘)[1].split(‘>’)[1].split(‘<‘)[0] company_location = listing.split(‘data-testid=”text-location”‘)[1].split(‘>’)[1].split(‘<‘)[0] print(f’title name: {title}’) print(f’company_name : {company_name}’) print(f’company_location : {company_location}’) total_data.append([title,company_name,company_location]) df = pd.DataFrame(total_data, columns=[“Title”,”Company Name”,”Company Location”]) print(df) df.to_excel(“d.xlsx”,index=False) df.to_csv(“d.csv”, index= False) |
Let’s break down what’s happening in this script:
- We split the HTML content at ‘aria-label=”full details of ‘ to separate individual job listings.
- For each listing, we extract the job title, company name, and location using carefully chosen split operations.
- We store the extracted data in a list and create a pandas DataFrame for easy manipulation and export.
Dive deeper into Python’s string methods here
Pros and Cons of This Approach
Like any technique, using the split method for web scraping has its advantages and drawbacks:
Pros:
- Lightweight and fast
- No additional libraries required for parsing
- Can be more resilient to minor HTML changes
Cons:
- Less robust than dedicated HTML parsing libraries
This complete scraper:
- Downloads the HTML content from Indeed.com
- Parses the content to extract job information
- Creates a pandas DataFrame with the extracted data
- Saves the data to both Excel and CSV formats
Conclusion
We’ve covered a lot of ground in this guide, from basic HTML parsing with Python’s split method to advanced techniques using Playwright. Whether you’re a job seeker looking to streamline your search or a data analyst gathering market insights, this Indeed.com scraper provides a solid foundation for your projects.
Remember, web scraping is a powerful tool, but it comes with responsibilities. Use these techniques wisely and ethically. Happy scraping!


{kind=link}