
Introduction
In today’s data-driven world, the ability to extract information from websites efficiently is a valuable skill. Whether you’re a budding developer, a seasoned programmer, or an AI enthusiast, mastering web scraping can open doors to countless possibilities. This guide will walk you through the process of web scraping using Playwright, a powerful and flexible tool that’s revolutionizing how we interact with web browsers programmatically.
Why Playwright for Web Scraping?
You might be wondering, “With so many web scraping tools out there, why should I choose Playwright?” Great question! Playwright offers several advantages that make it stand out from the crowd:
- Cross-browser support: Playwright works seamlessly with Chromium, Firefox, and WebKit, giving you unparalleled flexibility.
- Modern web compatibility: It handles dynamic content with ease, making it perfect for scraping JavaScript-heavy websites.
- Powerful automation: Playwright’s API is intuitive and robust, allowing for complex interactions beyond simple data extraction.
- Speed and efficiency: Its ability to run headless browsers makes it incredibly fast and resource-efficient.
For a deep dive into Playwright’s capabilities, check out the official Playwright documentation.
You may find the step-by-step video tutorial about this project on ▶️ YouTube.
Getting Started
Prerequisites
Before we dive in, make sure you have:
- Python 3.7 or higher installed on your system
- Basic knowledge of Python programming
- A text editor or IDE of your choice (I recommend VSCode or PyCharm)
- A curious mind and a cup of coffee (optional, but highly recommended)
Installation
Let’s get our environment set up:
- Open your terminal or command prompt.
- Install Playwright using pip:
| pip install playwright |
- Install the necessary browser drivers:
| playwright install |
Congratulations! You’re now ready to start your web scraping journey with Playwright.
Your First Scraper: A Step-by-Step Guide
Let’s create a simple scraper to extract product information from an e-commerce site. We’ll use B&H Photo Video as our example, but the principles can be applied to any website.
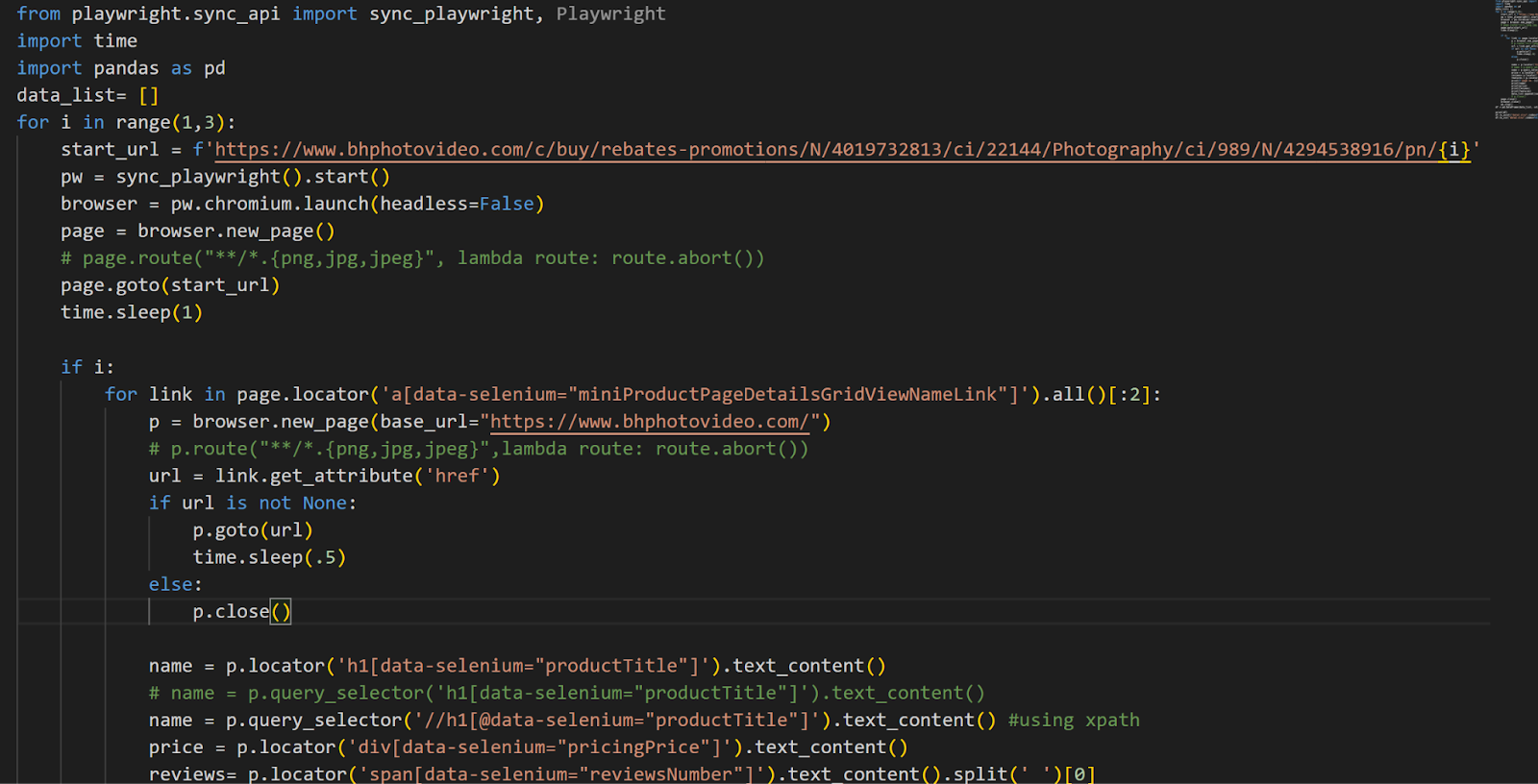
Step 1: Import Required Libraries
| playwright install from playwright.sync_api import sync_playwright import time import pandas as pd |
Step 2: Set Up the Browser
| def start_browser(): pw = sync_playwright().start() browser = pw.chromium.launch(headless=False) page = browser.new_page() return pw, browser, page pw, browser, page = start_browser() |
Step 3: Navigate to the Target Page
| start_url = ‘https://www.bhphotovideo.com/c/buy/rebates-promotions/N/4019732813’ page.goto(start_url) time.sleep(1) # Give the page time to load |
Step 4: Extract Product Links
| product_links = page.locator(‘a[data-selenium=”miniProductPageDetailsGridViewNameLink”]’).all()[:2] |
Step 5: Scrape Product Details
| data_list = [] for link in product_links: url = link.get_attribute(‘href’) if url: product_page = browser.new_page() product_page.goto(f”https://www.bhphotovideo.com{url}”) time.sleep(0.5) name = product_page.query_selector(‘//h1[@data-selenium=”productTitle”]’).text_content() price = product_page.locator(‘div[data-selenium=”pricingPrice”]’).text_content() reviews = product_page.locator(‘span[data-selenium=”reviewsNumber”]’).text_content().split(‘ ‘)[0] features = product_page.locator(‘ul[class=”list_OMS5rN7R1Z”]’).text_content() data_list.append([name, price, reviews, features]) product_page.close() browser.close() pw.stop() |
Step 6: Save the Data
| df = pd.DataFrame(data_list, columns=[“Name”, “Price”, “Reviews”, “Features”]) df.to_excel(“product_data.xlsx”, index=False) df.to_csv(“product_data.csv”, index=False) |
Best Practices and Tips
- Respect robots.txt: Always check a website’s robots.txt file to ensure you’re allowed to scrape it.
- Use delays: Add small delays between requests to avoid overwhelming the server.
- Handle errors gracefully: Implement try-except blocks to manage potential issues.
- Be ethical: Only scrape publicly available data and use it responsibly.
For more detailed information on web scraping ethics and best practices, check out this comprehensive guide on web scraping.
Common Challenges and Solutions
Challenge 1: Dynamic Content
Problem: Some websites load content dynamically using JavaScript.
Solution: Playwright excels at handling dynamic content. Use page.wait_for_selector() to ensure elements are loaded before scraping.
Challenge 2: CAPTCHAs
Problem: Websites may use CAPTCHAs to prevent automated access.
Solution: Implement CAPTCHA-solving services or use proxy rotation. For more advanced solutions, consider Playwright’s network interception capabilities.
Challenge 3: Rate Limiting
Problem: Websites may block your IP if you make too many requests.
Solution: Implement delays between requests and consider using a pool of proxy servers to distribute your requests.
Advanced Techniques
As you become more comfortable with Playwright, you can explore advanced features like:
- Parallel scraping: Use asyncio with Playwright to scrape multiple pages simultaneously.
- Headless mode: Run browsers in headless mode for faster scraping.
- Custom user agents: Rotate user agents to mimic different browsers.
For a deep dive into these advanced techniques, check out the Playwright API documentation.
Conclusion
Web scraping with Playwright opens up a world of possibilities for data collection and analysis. By following this guide and practicing regularly, you’ll soon become a web scraping expert. Remember to always scrape responsibly and ethically.
Happy scraping, and may your data be clean and your requests always successful!
Frequently Asked Questions (FAQs)
1. What is Playwright, and why should I use it for web scraping?
Answer: Playwright is a powerful tool for automating web browsing tasks. It’s designed to provide a fast and reliable way to scrape websites, test web apps, and perform any task that requires interacting with a browser. Compared to other tools like Selenium, Playwright offers better support for modern web features, multi-browser support, and a more consistent API1.
2. How do I set up Playwright for Python on my computer?
Answer: To get started with Playwright, you’ll need Python 3 installed on your computer. You can set up your environment using a virtual environment tool like Poetry. Here’s a quick setup guide:
- Install Poetry: pip install poetry
- Initialize a new project: poetry init
- Add Playwright to your project: poetry add playwright
- Install Playwright browsers: poetry run playwright install
3. How do I write my first web scraping script with Playwright?
Answer: Writing your first script is simple. Here’s a basic example to get you started:
| from playwright.sync_api import sync_playwright def run(playwright): browser = playwright.chromium.launch() page = browser.new_page() page.goto(“https://example.com”) content = page.content() print(content) browser.close() with sync_playwright() as playwright: run(playwright) |
This script launches a Chromium browser, navigates to a website, and prints the page content.
4. How can I handle dynamic content with Playwright?
Answer: Playwright includes built-in waiting mechanisms to handle dynamic content. You can use methods like page.wait_for_selector() to wait for elements to load before interacting with them. This helps ensure your scraper captures all necessary data.
5. What are some best practices for web scraping with Playwright?
Answer: Here are a few best practices:
- Respect website terms of service: Always check the website’s terms of service to ensure you’re allowed to scrape it.
- Use headless mode: Running your scraper in headless mode (without a GUI) makes it faster and more efficient.
- Implement retries: Add retry mechanisms to handle network issues or temporary website downtimes.
- Avoid overloading the server: Use delays between requests to avoid overwhelming the server and getting blocked.
6. How can I make my Playwright scripts more robust?
Answer: To make your scripts more robust, consider:
- Error handling: Use try-except blocks to handle exceptions gracefully.
- Logging: Implement logging to keep track of your scraper’s activities and troubleshoot issues.
- Modular code: Break your code into functions and modules to make it easier to maintain and update.


{kind=link}